

导读 在咫尺快速发展的数据分析领域,智能分析平台正履历从传统 BI 到敏捷分析,再到智能分析的革新。随着移动互联网的兴起和大言语模子的出现,数据分析变得更加普及,用户可以通过当然言语与系统进行互动,获取所需数据。然则,即使在敏捷分析阶段,仍然存在一定的学习本钱。大言语模子的引入为数据分析带来了新的机遇,它不仅擢升了言语认识和生成才调,还使得逻辑推理与器具使用变得更加高效。通过对用户当然言语指示的认识和升沉,智能分析平台能够已毕更直不雅的数据查询和分析过程,为用户提供更为方便的管事。本文将共享腾讯基于 LLM 的智能数据分析平台 OlaChat 的落地实践。
主要内容包括以下几大部分:1. 从传统 BI 到智能 BI
2. LLM 时间智能 BI 的新可能
3. 腾讯 OlaChat 智能 BI 平台落地实践
4. 问答重要
共享嘉宾|谭云志 腾讯 高档研究员
裁剪整理|陈念念永
内容校对|李瑶
出品社区|DataFun
01从传统 BI 到智能 BI
随着大言语模子(Large Language Models, LLMs)的快速发展,智能分析在生意智能(Business Intelligence, BI)领域的影响日益权臣。本节将研究从传统 BI 到智能 BI 的过度过程,分析这一排型所带来的新机遇与挑战。
1. 传统 BI 的局限性
传统的生意智能体系频繁是基于一种从上至下的模式,业务精采东谈主提议需求,设备东谈主员进行数据索取和分析,最终经过一段时期的设备后,将罢休响应给业务方。这种过程不仅效能低下,还存在较大的相易本钱,导致决策的延伸。用户时常需要恭候一周甚而更长的时期,才能得到所需的数据分析罢休。2. 移动互联网时间的敏捷分析随着移动互联网的崛起,数据的丰富性和复杂性不断增多,市集对数据分析的需求也在发生变化。敏捷分析应时而生,它旨在使更多的用户能够方便地获取数据并进行自助分析。通过粗拙的拖拽操作,用户可以放松进行数据探索。然则,调研袒露,即即是这种粗拙的操作,对某些用户来说依然存在较高的学习本钱。比如,用户在进行环比策画或其他复杂操作时,仍需掌抓关系功能的使用方法,存在一定的门槛。3. 智能 BI 的初步探索
到了 2019 年,智能分析的构想开动萌芽。固然大言语模子尚未全面普及,但一些在当然言语处理领域进展细密的模子照旧出现。这一时期,业界开动温顺若何让更多的用户能够放松进行数据分析,方向是将每个东谈主都革新为“数据分析师”。智能分析的看法逐渐酿成,致力于于简化数据分析过程,裁减用户的时期门槛。现如今,随着大言语模子的普及,智能BI 迎来了新的发展机遇。大言语模子不仅能够处理复杂的数据查询,还能通过当然言语与用户进行交互,使得数据分析变得更加直不雅和东谈主性化。用户只需用当然言语描绘他们的需求,系统便能自动生成相应的分析罢休,这大大提高了分析的效能和准确性。02LLM 时间智能 BI 的新可能
大言语模子(Large Language Models, LLMs)的发展历程展现了当然言语处理(NaturalLanguage Processing, NLP)领域的权臣越过。接下来将梳理大言语模子的发展线索,并研究其对数据智能分析所带来的新机遇。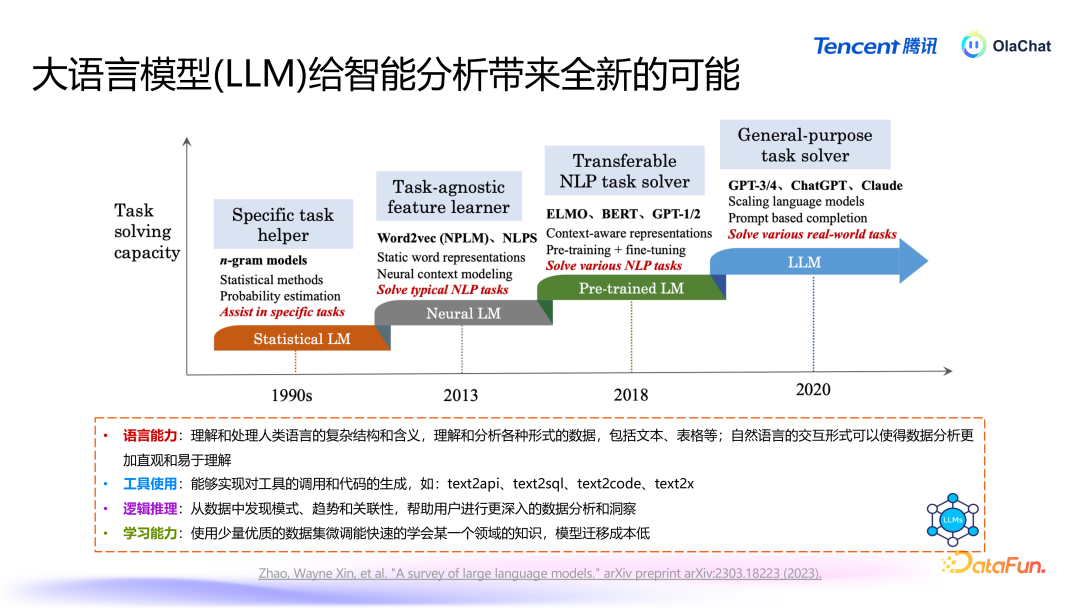
1. 大言语模子的发展线索
(1)初期阶段:基于概率的言语模子当然言语处理的早期阶段主要依赖于概率模子,如条目迅速场(Conditional Random Fields, CRF)和马尔可夫模子。这些模子基于历史数据,通过词袋模子(N-gram Model)来策画词语出现的概率。此时,言语模子的才调相对有限,主要侧重于基于历史词语的概率展望。(2)神经会聚时间的崛起2013 年,谷歌发布了一项具有里程碑酷好的方法 word2vec,鲜艳着基于神经会聚的言语模子时间的到来。在这一阶段,短耐久挂牵会聚(Long Short-Term Memory, LSTM)等模子开动得到鄙俗应用。神经会聚的引入大大提高了言语模子的性能,增强了其对高下文的认识才调。(3)Transformer 模子的兴起2017 年,Google 发布了 Transformer 架构,由此在 2018 年前后出现了一系列基于此的模子,如 BERT、GPT1/2 等。相较于之前的模子,BERT 和 GPT1/2 模子的参数目权臣增多,达到千万、数亿畛域。这些模子通过在大量语料上进行救济熟谙,可以快速妥贴不同任务,展现出浩大的言语认识才调。(4)现时的万亿参数时间随着 GPT-3 和后续版块的推出,言语模子的参数目达到了千亿、万亿级别。这使得一个模子能够同期在多个任务上达到较好的效能,裁减了对多个模子的依赖。在这一阶段,言语模子在文本生成、认识和逻辑推理等方面的才调都得到了极大的擢升。2. 大言语模子对数据智能分析的影响
大言语模子为数据智能分析带来了以下四个方面的检阅:言语才调:大言语模子在言语认识和生成方面的才调相配浩大。它能够灵验解读文本和表格数据背后的含义,使得数据分析变得更加直不雅、易于认识。通过当然言语交互,用户可以更放松地进行数据分析,而不需要深切掌抓复杂的器具和时期。器具使用:大言语模子能够将用户的指示升沉为器具调用或代码生成。举例,用户可以通过粗拙的当然言语请求,生成相应的 API 调用或代码。这种才调权臣提高了数据分析的效能,裁减了时期门槛。逻辑推理才调:尽管大言语模子的逻辑推理才调相对有限,但它在模式识别、趋势分析和关联性发现方面仍然进展出色。这为数据智能分析提供了有劲解救,使得用户能够从数据中索取有价值的知悉。学习才调:在早期,熟谙一个模子以妥贴特定任务频繁需要大量的数据。然则,收成于大言语模子的“高下文体习”(In-contextLearning)才调,用户不需要进行模子熟谙也能在一些任务上取得可以的效能。即使需要微调,用户也可以通过较少的数据(仅需几千条)就能诊疗模子以原意特定需求,这种妥贴性使得大言语模子在各种任务中的应用变得更加生动。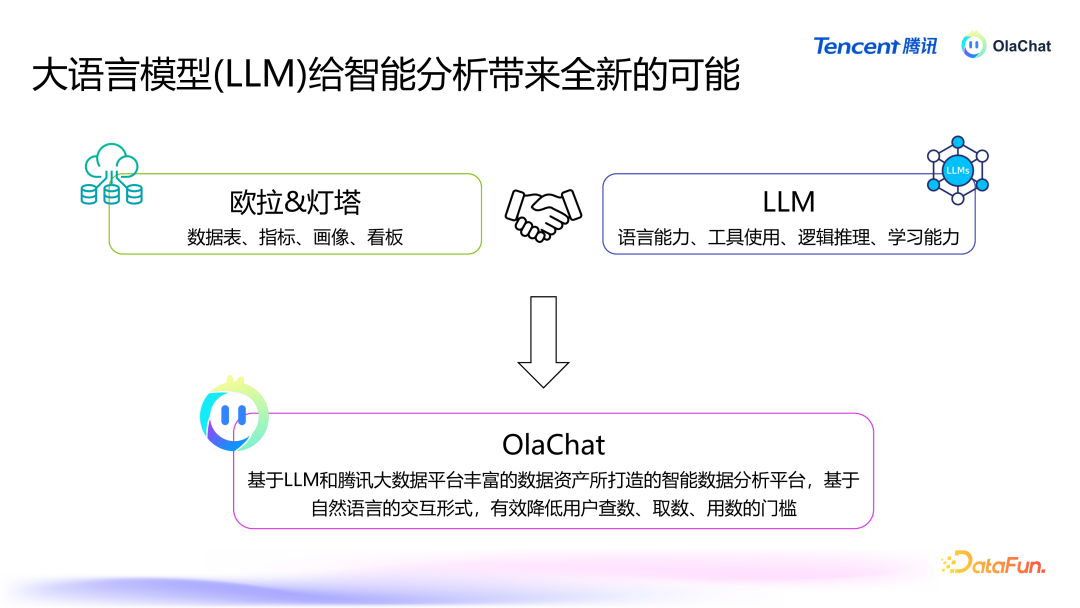
基于腾讯PCG 大数据平台部钞票经管平台“Ola”和数据分析平台“灯塔”丰富的元数据和用户行径日记,筹商大言语模子的才调,咱们构建了 OlaChat 这一智能数据分析平台。OlaChat 能够提供高效和智能的数据分析管事,原意用户问数、东谈主群知悉、NL2SQL 等需求,灵验裁减了查数、取数、用数的门槛。接下来将详备先容 OlaChat 平台落地实践。03腾讯 OlaChat 智能 BI 平台落地实践
OlaChat 智能数据分析平台主要方向是通过当然言语交互,为用户提供畅达的数据分析体验。系统的中枢模块包括多任务对话系统、任务编排引擎、盛大的 AI 器具以及底层的群众管事才调。以下是 OlaChat 的重要功能与时期架构的深切领悟。1. OlaChat 重要才调
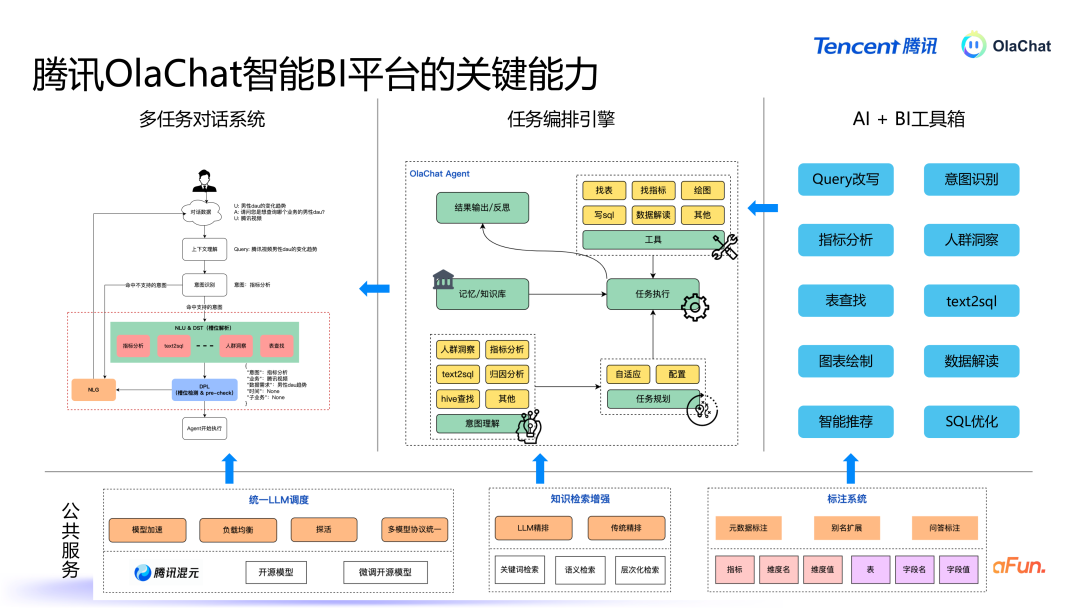
多轮对话系统:用户与 OlaChat 交互的第一进口是一个多任务对话系统,雷同于智能助手,用户通过当然言语与系统进行交互,系统需要具备认识用户意图并履行关系任务的才调。任务编排与履行:系统认识用户意图后,磋磨出履行任务所需的方法,并按措施调用关系器具和数据。AI+BI 器具箱:包括 Query 改写、text2SQL、主见分析等器具,这些器具通过不同的组合可以已毕不同的才调,从而惩办不同的任务。群众管事:底层由一些群众管事来扶持关系才调,主要包括三个部分:救济 LLM 调遣(包括腾讯的混元模子,以过甚他一些微调过的模子),系统设立了救济的模子调遣机制,笔据不同任务自动采用合适的言语模子,并进行负载平衡和模子加快,针对不同模子输入输出的姿色互异,系统通过群众管事屏蔽这些互异,提供一致的交互接口。学问检索增强:提供了检索元数据的功能。标注系统:在数据分析过程中需要处理大量与特定领域关系的数据,因此引入了标注系统,可以对自界说数据和主见进行标注,用于增浩大言语模子的领域认识才调。接下来将具体先容其中一些才调。2. 多任务对话系统
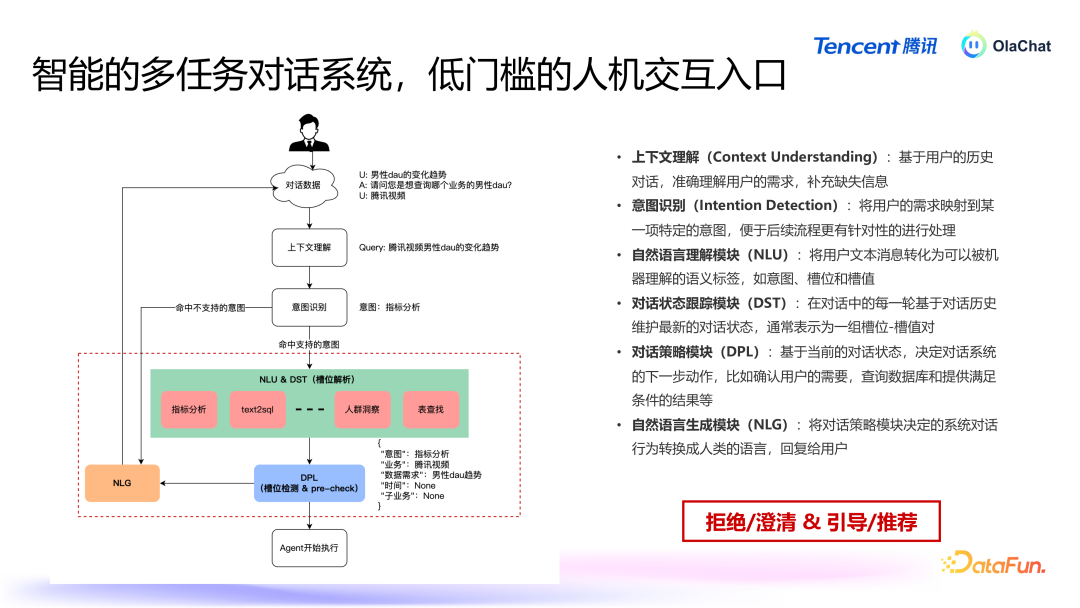
多任务对话系统提供的基础功能为拒却/廓清,以及教诲/保举。系统具备的重要才调包括:高下文认识:不竭追踪高下文,基于用户的历史对话,准证实识用户的需求,补充缺失信息。意图识别:基于高下文认识,进行意图识别,将用户需求传到对应的 Agent。当然言语认识模块(NLU):将用户文本音信升沉为可以被机器认识的语义标签。对话景象追踪模块(DST):在对话中的每一轮基于对话历史崇尚最新的对话景象,频繁示意为一组槽位-槽值对。对话计谋模块(DPL):基于现时的对话景象,决定对话系统的下一步作为。当然言语生成模块(NLG):将对话计谋模块决定的系统对话行径转化为东谈主类语音,恢复给用户。3. 元数据检索增强
在数据分析中,元数据的检索是一个重要方法,尤其当数据呈现结构化姿色时,传统的基于非结构化当然言语的检索方法无法填塞适用。腾讯的智能分析平台通过增强元数据检索才调,惩办了结构化数据中的多条理、复杂性问题,为用户提供更精确的分析解救。
结构化数据,比如表和主见,每个表有表名、字段,主见下有维度(如年纪、性别等),这些数据有条感性和明确的结构。这种条理结构不同于非结构化文本,弗成粗拙地通过当然言语的检索增强方法来处理。传统的当然言语检索主要基于 embedding(镶嵌向量)时期,将文分内块后,通过雷同度匹配来检索关系信息。然则,结构化数据并不投诚当然言语的逻辑,导致传统方法难以平直应用。通用RAG 在惩办元数据检索增强任务时存在一定的不适用性,主要因为:元数据是按特定的结构、条理组织的。主见、字段、维度的组合莫得固定的前后措施或当然言语中的常见法例。如当然言语中“中国的都门是“,后头随着的约略率会是“北京”,然则元数据并不适当言语模子的基本假定。特定修藉端很遑急,某些特定的字段或维度常常具关联键性酷好,比如“灵验播放次数”和“付费播放次数”示意的是截然有异的主见,这种互异无法通过传统的检索格式精确捕捉。字段名可以很短,这就要求检索方法能准确地拿获用户问题中的重要信息。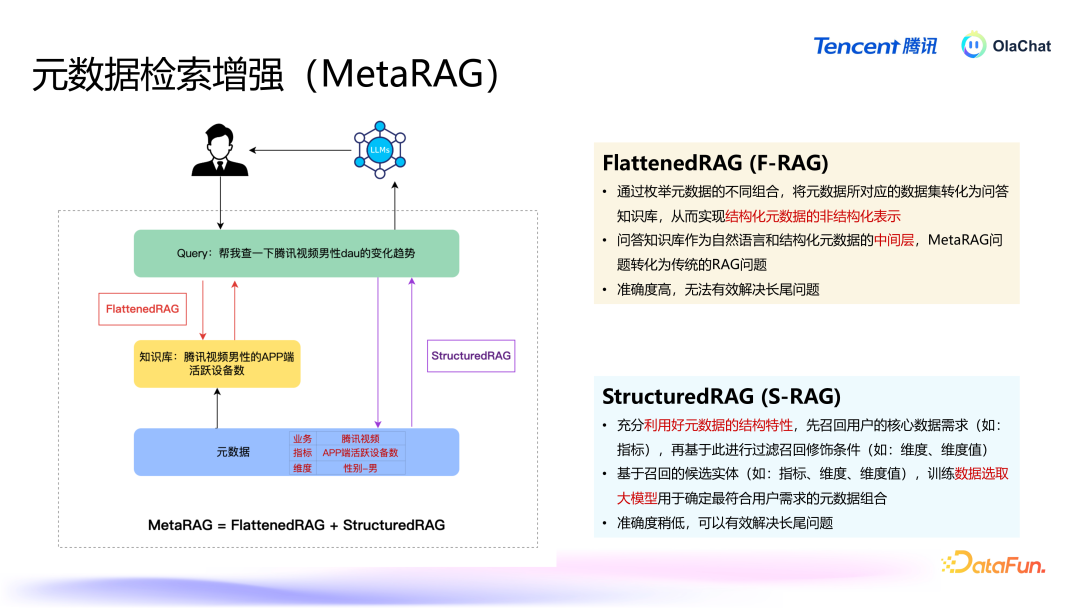
咱们有两种决策,分别从两个角度来惩办元数据检索增强的问题。第一种决策是 FlattenedRAG,在已有元数据基础上进行组合,将结构化的元数据变为非结构化的当然言语,当给与到用户问题后,进行检索、排序,找到与学问库中一致的数据。第二种决策是 StructuredRAG,充分诈欺好元数据的结构化信息,优先检索出最中枢的元素,再围绕这些中枢元素进行二次检索,找到所需的数据。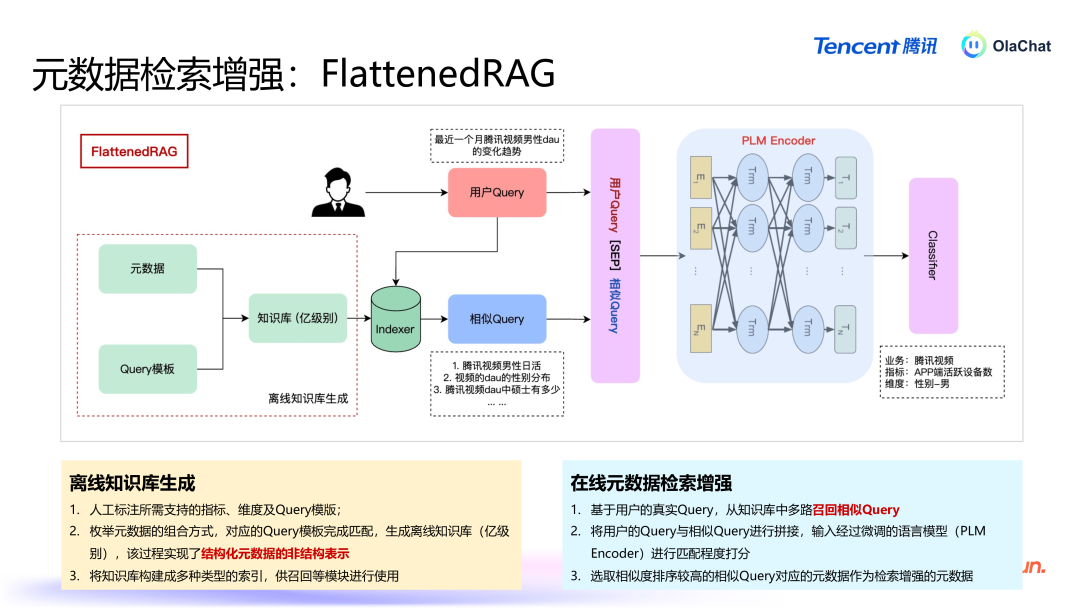
FlattenedRAG 的具体过程如下:元数据打平:将数据表、字段、主见等信息组合成雷同于问答式的当然言语。举例,主见为“活跃用户数”、维度为“男性”的查询组合可能会被打平为:“腾讯视频男性活跃用户数有几许?”。基于学问库进行检索:当用户提议问题后,系统会从打平后的学问库中进行检索,找出与用户问题雷同的文本。排序和匹配:系统通过预熟谙的分类模子对检索罢休进行排序,最终采用出最关系的谜底复返给用户。这种方法的中枢在于将结构化信息升沉为非结构化文本,从而使得传统的当然言语检索时期可以平直应用。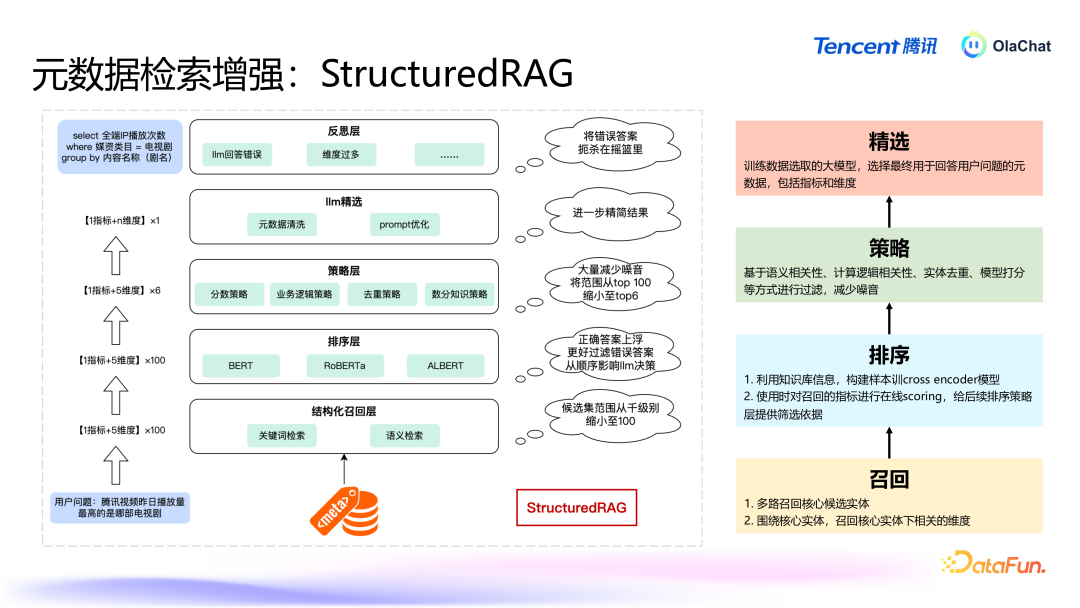
StructuredRAG 的主要过程如下:中枢元素的检索:当用户提议问题时,系统治先会诈欺结构化信息的条感性,优先检索出最遑急的元素,如主见、维度等。举例,在用户盘问“腾讯视频的男性活跃用户有几许”时,系统会领先服气“活跃用户数”这个重要主见。围绕中枢元素的进一步检索:在找到中枢元素后,系统会进行二次检索,匹配用户的问题和中枢元素的其他关系信息,比如在上头的例子中会二次检索和“男性”雷同的多个维度。复返罢休:系统笔据中枢元素的检索罢休,再筹商进一步的二次搜索,临了经过一次排序之后给出最适当用户问题的谜底。两种方法各有优纰谬:打平素法:通过将结构化数据打平为非结构化文本,简化了复杂的数据结构,方便了当然言语处理的应用。此方法的上风在于能够平直诈欺已有的当然言语检索时期,操作浅易,但是如若主见和维度的数目相配多时该方法可能会濒临组合爆炸的问题。结构化方法:充分诈欺了元数据的条理结构信息,能够在保持数据条理关系的同期提高检索的准确性。此方法在处理相配复杂且条理分明的数据时更加灵验,尤其是包含多个维度的长尾问题。在骨子应用中,这两种决策各有其适用场景。举例,当主见和维度的数目相对有限时,打平素法可能更为高效;而在主见和维度组合较多的场景下,结构化方法例能够提供更解放的检索格式。这两种决策的筹商,使得系统能够在不同场景下生动叮属用户提议的各式数据分析需求。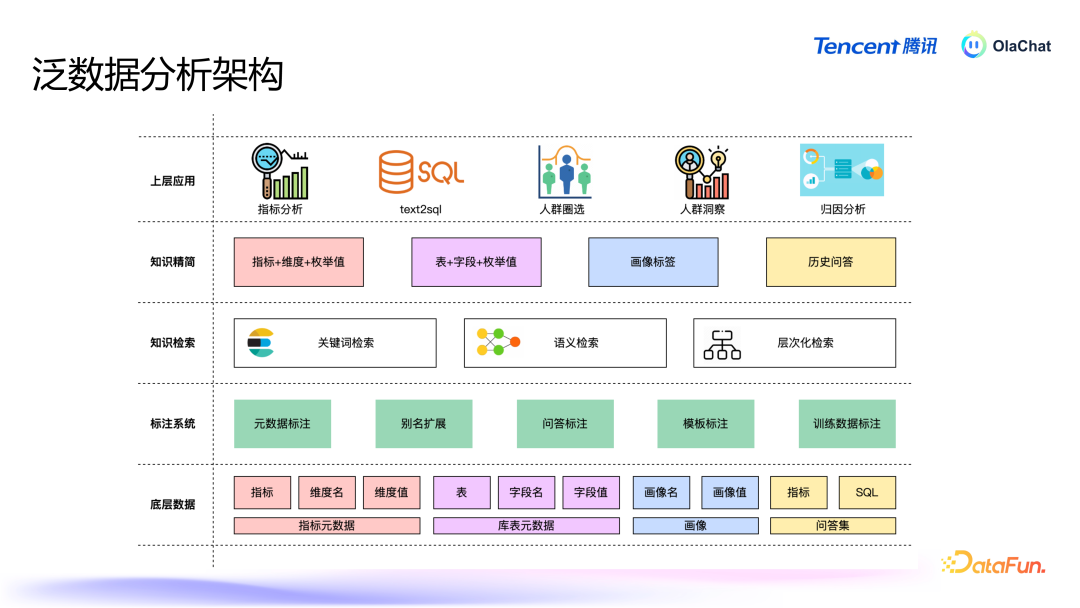
在泛数据分析架构中,底层是主见、库表等元数据,以及画像和历史问答集;这些数据过问标注系统后,会经过各式标注处理;之后是各式检索,包括重要词检索、语义检索等;检索后进行学问精简,继而为表层的主见分析、东谈主群圈选等各式应用提供解救。学问精简和学问检索就是由前边先容的元数据 RAG 已毕的。4. Text2SQL
Text2SQL 着实业务场景下存在着诸多问题:领先,数据狡饰与安全遥远是不可逾越的红线。举例,一些有名模子在使用契约中规则,企业如若月活跃用户数稀奇一定数目,就必须请求使用权限。这关于腾讯等大企业而言,意味着很多闭源和开源模子都不可用,因此必须设备自有模子以原意业务需求。尽管大型言语模子在时期上进展浩大,但在业务认识方面却存在权臣不及。很多企业的数据质地较低且结构重大,模子很难准证实识。此外,模子时常穷乏领域学问,可能会产生“幻觉”。另外,模子的平安性和准确率也存在不及。着实情况下用户问法相配个性化,现存决策的抗噪声才调不及(BIRD~70%),导致平安性和准确率较差。企业在骨子应用中时常难以获取到高质地数据,尤其是冷启动阶段,高质地的 query 到 SQL 的数据相配匮乏。基于上述问题,咱们最终采选了微调大模子+Agent 的决策来已毕 Text2SQL。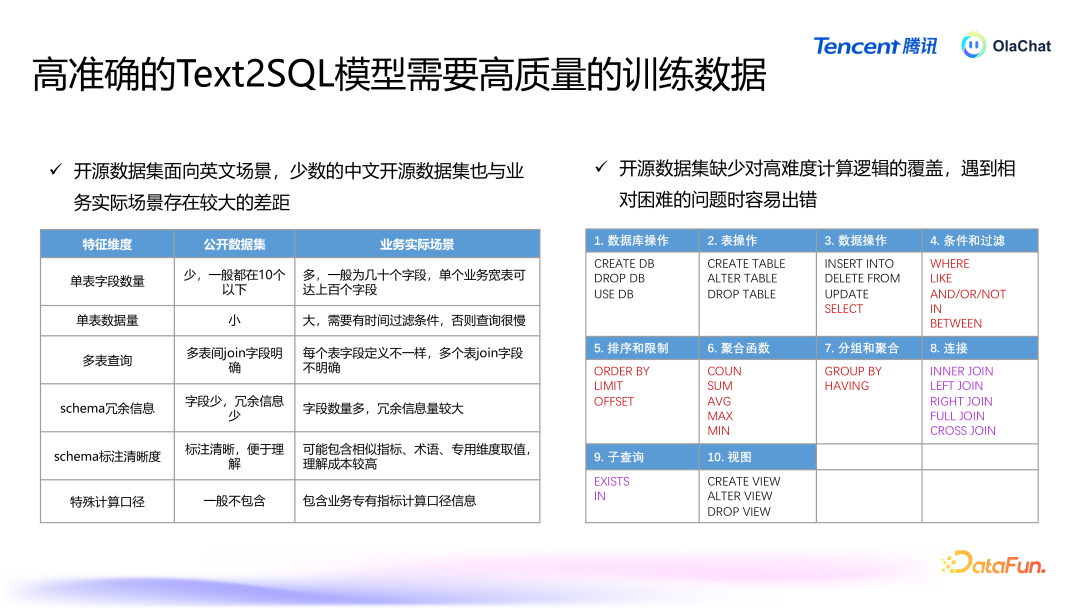
高质地的数据关于熟谙高效的模子至关遑急。然则,开源数据集大多面向英文场景,即使翻译成汉文,结构也较为粗拙,频繁为单表,字段在 10 个以下,而骨子业务场景中可能有上百个字段。这使得大型模子在处理这些数据时容易产生诬陷或无法准确解读业务中的复杂逻辑。此外,开源数据集在操作符的使用上也相比有限,常用的操作符较少,这进一步裁减了模子在复杂任务上的进展。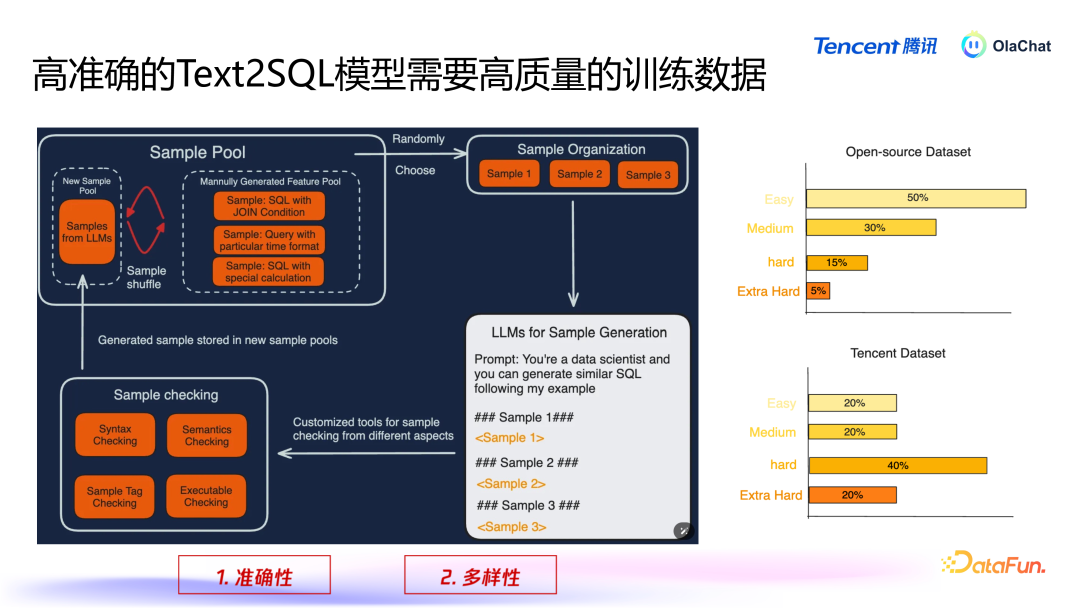
在咱们里面,照旧设立了一套数据生成的逻辑过程。该过程主要包括以下几个方法:数据采集与脱敏:领先,咱们会基于采集到的腾讯里面数据,进行必要的脱敏处理,以确保用户狡饰和数据安全。迅速选取数据:在经过脱敏处理后,咱们会从数据皆集迅速采用一些样本,并将这些样本拼接成雷同的指示(prompt),然后输入到大型模子中。数据增强:诈欺这些样本,咱们会使用数据增强的方法,让模子基于已有样本生成新的样本,通过这种轮回不断丰富数据集。在数据增强过程中,有两个重要点需要终点温顺,即准确性和各种性。准确性:咱们必须确保大型模子生成的 SQL 是准确的。如若模子生成的 SQL 失误并被加入熟谙集,就会导致模子性能着落。因此,咱们瞎想了一套代码逻辑来查验生成的 SQL 是否正确,领先这个 SQL 要能够履行,况兼与用户输入的查询语义相匹配,为此咱们使用一个有利的模子来考据生成查询的语义正确性。各种性:咱们还需要确保数据的各种性,幸免模子生成大量雷同的数据。为此,咱们继承了一些雷同性检测的方法,剔除过于雷同的样本。此外,咱们会对生成的数据进行分类,确保各种别之间的平衡。如若某个类别的数据过多,咱们会减少该类别的生成;而关于数据较少的类别,则会重心生成更各种本,以擢升数据集的全体准确性和各种性。在数据生成过程中,咱们将样本分手为不同的难度等第,包括粗拙(easy)、中等(medium)、艰辛(hard)和终点艰辛(extra hard)。咱们发现,开源数据集在艰辛和格外艰辛的数据生成上散播不均。因此,咱们终点重心生成这些艰辛类型的数据,以弥补开源数据集的不及。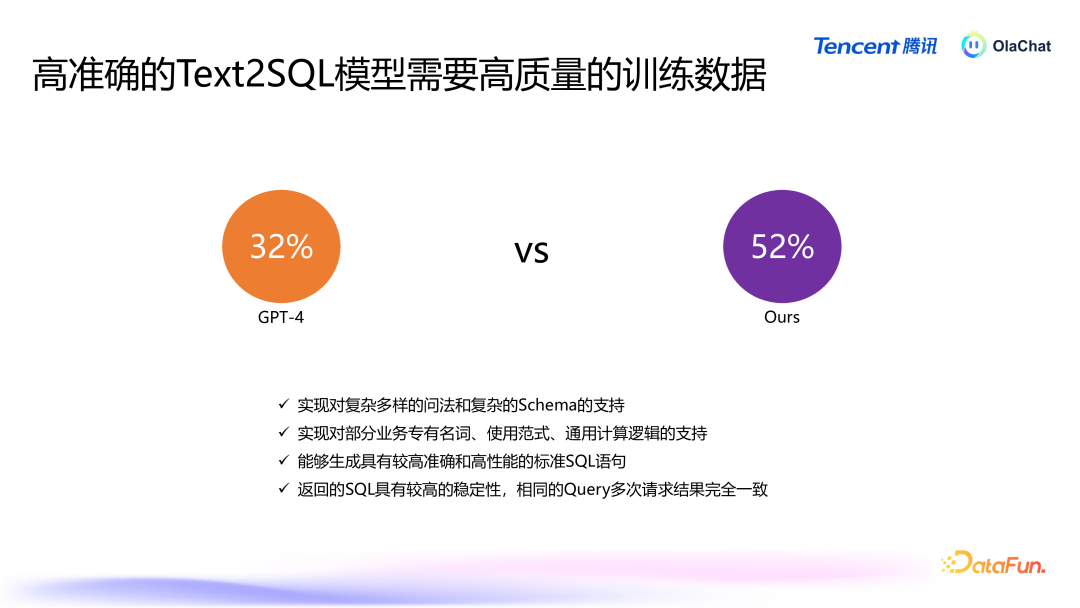
经过这么的数据增强与补充后,咱们对模子的进展进行了评估。在着实的业务数据集上,模子的准确率频繁较低,举例,GPT-4 的准确率为 32%,而咱们我方的模子可以达到 52%。除此以外,咱们熟谙的模子还能已毕对复杂问法、复杂 Schema 和复杂策画逻辑的解救,具有较好的平安性。
咱们还发现,单独使用一个模子很难达到逸想效能,原因如下:数据集障翳不全:业务中的各式查询可能相配复杂,而咱们很难障翳通盘同学所编写的查询样本。言语各种性与歧义:用户的言语抒发多种各种,可能存在歧义和同义词,使得生成的查询难以原意通盘需求。杂音与信息热闹:在数据皆集,存在一些杂音数据,这些信息会热闹模子的熟谙效能。在咱们的系统中,除了依赖于大型模子外,咱们还设备了一套智能体过程,旨在辅助大模子生成更高质地的 SQL。这个智能体的过程能够针对大模子在认识力、平安性和准确率等方面的不及,实施相应的计谋,以惩办这些问题。减少冗余信息,引入辅助信息咱们意识到,将一张表的一起字段都传递给大型模子以供其认识并不推行。为了提高模子的准确性,咱们会领先进行字段的精选,过滤掉冗余字段,留住更关系的字段,从而使得模子在认识时更加皆集庸高效。适当融入传统模子/计谋用户的问题表述常常较为玩忽,为了擢升准确性,咱们可以通过模子对用户输入的问题进行模范化处理,并加入一些 fewshot 检索,从而提高模子的认识才和洽生成准确性。对模子罢休进行后验优化生成的 SQL 可能并不老是能正确履行,咱们瞎想了一个后续纠错机制,诈欺大模子对生成的 SQL 进行审核,并进行必要的修改,同期可以进一步擢升准确性。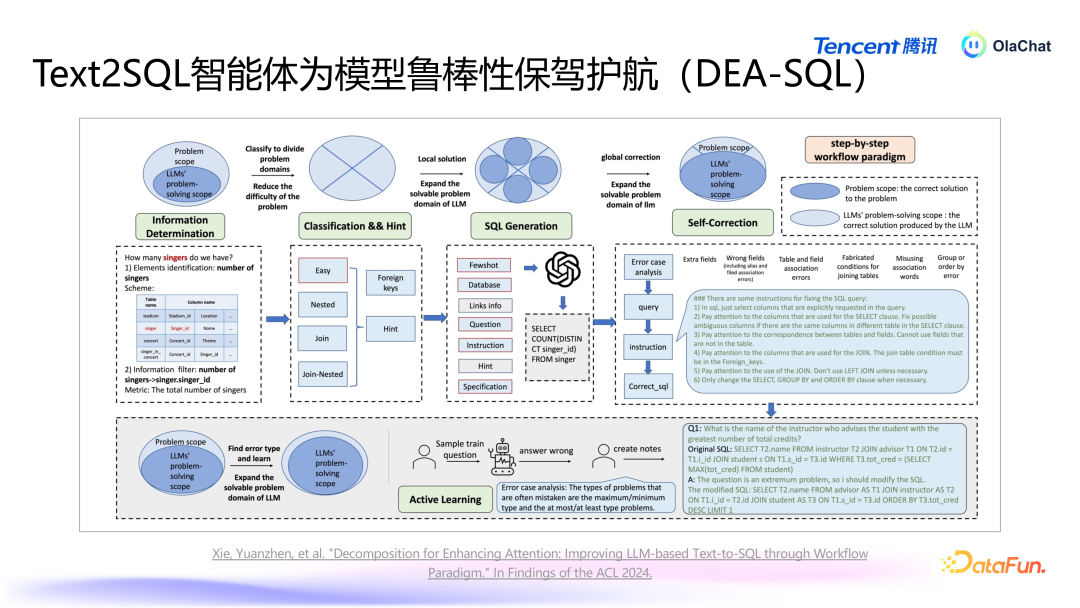
咱们将上述念念想整合成了一篇论文,研究了若何通过信息精简、分类处理、针对性生成和自我纠错的过程来擢升模子性能。在生成过程中,对不同复杂进度的查询采选不同处理格式,粗拙的查询与复杂的查询应有不同的生成计谋。在生成时设定特定条目,确保生成查询适当履行要求。同期,实施自我纠错机制,让模子对我方生成的查询进行反念念与诊疗。此外,咱们还实施了主动学习(active learning)的计谋,针对常见问题进行重心指示。通过让模子专注于模范化问题,进一步提高模子的准确性。这一过程将智能体与大型模子相筹商,擢升全体的准确率。5. Text2SQL 以外
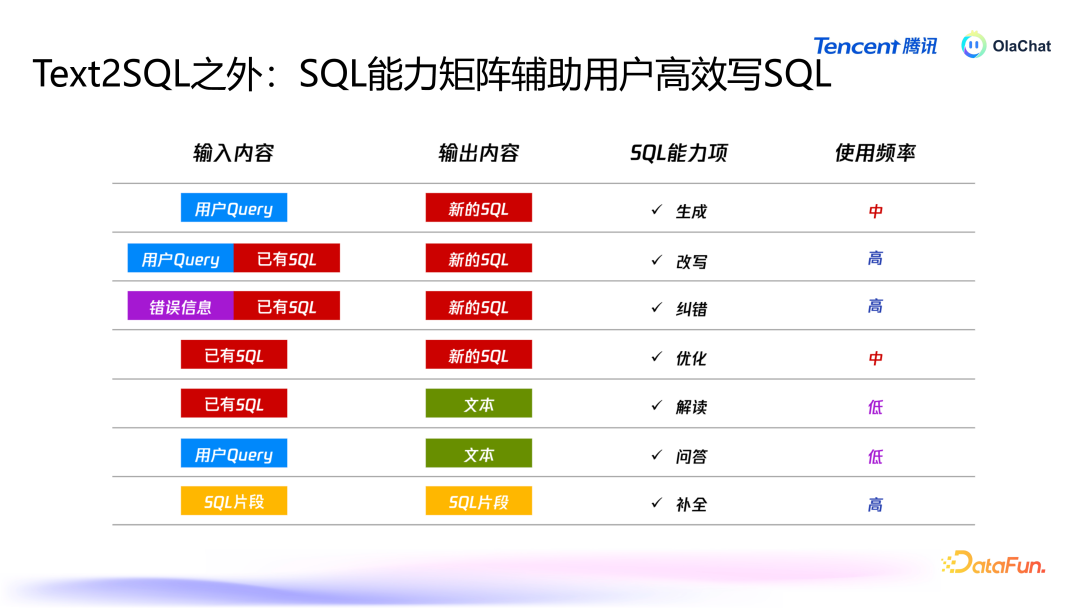
在进行智能分析时,用户的需求不仅限于 text2SQL,还会有改写、纠错、优化、解读、问答、补皆等多种需求。为了原意用户多元化的需求,咱们在系统中构建了多个智能体,旨在辅助用户进行数据智能分析,擢升效能。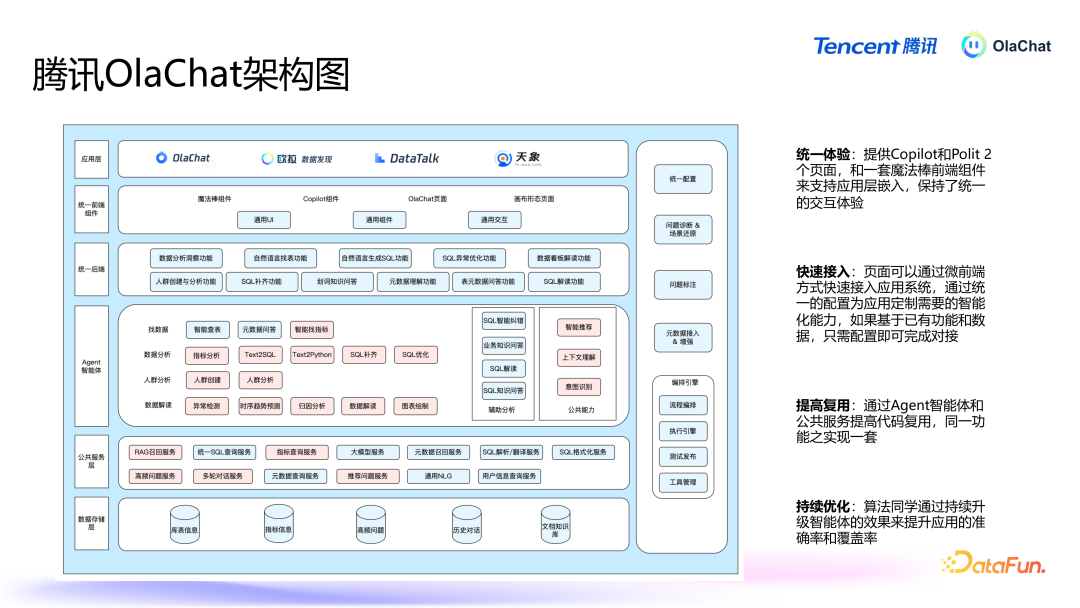
上图展示了 OlaChat 的全体架构,从下到上包括底层管事、中间群众管事、Agent、救济后端、救济前端,以及所解救的各式应用。不同模块相互联接,已毕通盘平台的救济体验,擢升用户在数据分析过程中的效能与效能。04问答重要
Q1:取数时使用了多大的模子?A1:取数模子为 8B,相对较小,妥贴快速判断用户的查询。NL2SQL 继承的是 70B 的模子进行微调。Q2:若何保证归因的准确率?A2:归因的准确率依赖于归因器具。固然大模子推理才调强,但要筹商外部数据提高准确率。是以咱们的作念法为,基于归因器具拿到数据后,大模子精采在中间串联,作念一些言语上的整理归纳,呈现给用户。Q3:SQL 纠错和 SQL 解读是否用了大模子?A3:SQL 纠错息争读是用大模子已毕的,但仅用大模子的话准确率较低,因此需引入更多信息来优化。比如可以加入 SQL 顶用到的表的元数据,也可以将履行中的报错信息加入进去。是以弗成光用大模子,而是要笔据具体场景加入更多信息。Q4:平直生成 SQL 语句是否过于复杂?A4:平直生成 SQL 语句与基于语义层的简化方法各有上风,前者生动性高,后者妥贴对不熟悉 SQL 的用户提供了灵验的提效决策。以上就是本次共享的内容,谢谢巨匠。
共享嘉宾
INTRODUCTION
谭云志
腾讯
高档研究员
腾讯 PCG 大数据平台部智能数据分析(ABI)平台算法精采东谈主,精采从 0 到 1 已毕 AI 算法在数据分析平台的落地,在大言语模子、对话系统、text2sql 、保举系统等方面有较深切的研究。毕业于清华大学,先后履新于 LinkedIn、探探、腾讯,有近 10 年算法研究和算法居品落地训诲。