智子引擎开源多模态MoE大模子,可高效彭胀模子容量

转载整理自 智子引擎
量子位 | 公众号 QbitAI
跟着多模态大模子的快速发展,面前主流多模态大模子具备完成多种任务的能力(图文形色、视觉问答、翰墨识别、图标认知、宗旨检测等)。然而,这些不同的多模态任务时时具有皆备不同的数据分散,导致在模子历练经由中遭遇“多任务冲破”的问题,尤其在模子参数目较小时,这种问题尤为凸起。如何才能在有限加多模子参数目以及历练资本的条目下,高效地彭胀模子容量,缓解多模态大模子“多任务冲破”问题?
近日,针对这一挑战,来兴隆模子初创公司智子引擎的扣问团队开源了基于MoE架构的多模态大模子Awaker2.5-VL。Awaker2.5-VL通过确立多个巨匠,彭胀了模子在不同任务上的能力,灵验地缓解了多模态“多任务冲破”的问题。该模子还对MoE中门控聚集的路由策略进行了致密的扣问,并盘算了一个简短且相配灵验的路由策略,提高了模子历练的褂讪性。现在,Awaker2.5-VL的论文和代码也曾公开,后续还会更新更强的版块。

论文地址: https://arxiv.org/abs/2411.10669
代码仓库: https://github.com/MetabrainAGI/Awaker

模子架构
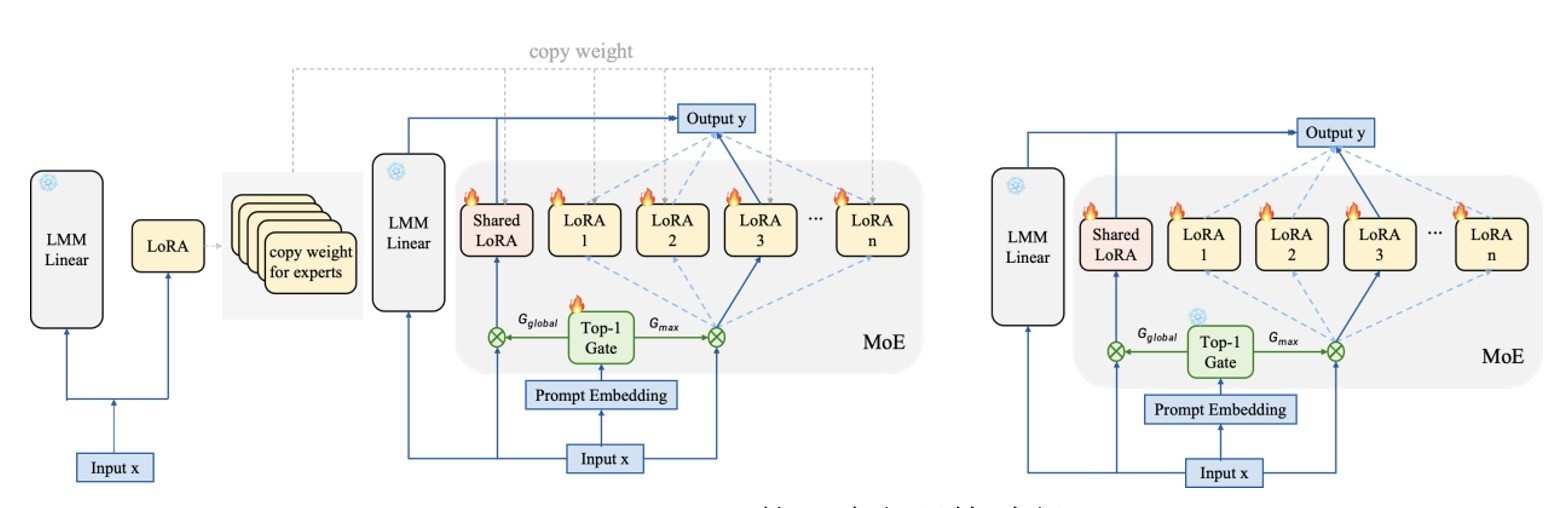
Awaker2.5-VL剿袭参数高效的LoRA-MoE架构,如下图(左)所示。该架构包含多个Task Expert和一个Global Expert,离别学习专用常识和通用常识,每个巨匠都是一个LoRA结构。此外,该架构还包含一个门控聚集用于抑制巨匠的激活。这种MoE架构不错在Attention、MLP等结构中实行快速插入的操作,而且还不错通过调遣每个LoRA的秩自行调遣模子的参数目。Awaker2.5-VL还盘算了一个简化版的MoE架构,如下图(右)所示,在这个简化版MoE中,门控聚集被移除,而是由其它层MoE分享的路由收尾抑制巨匠的激活。Awaker2.5-VL在基座模子中的不同模块穿插使用这两种MoE架构。

Awaker2.5-VL剿袭的两种MoE架构
Awaker2.5-VL针对MoE架构中门控聚集的路由策略进行了扣问,并盘算了一种简短且灵验的Instance-level的路由策略。该策略将图片和问题的Embedding当作门控聚集的输入,而且为了保合手历练和推理时路由的一致性,历练时数据中的label部分不参与路由。此外,与传统MoE不同的是,Awaker2.5-VL每一层MoE的门控聚集都分享同样的输入。这种简短高效的路由策略缩小了模子的复杂度,提高了模子的褂讪性。
模子历练Awaker2.5-VL以Qwen2-VL-7B-Instruct当作基座模子进行达成,总模子参数目为10.8B。历练分为三个阶段,如下图所示。第一阶段,动手化历练。在该阶段基座模子被冻结,并确立一个单LoRA进行历练。第二阶段,MoE历练。该阶段进行通盘这个词MoE模块的历练(包括每个巨匠和门控聚集),其中每个巨匠都使用第一阶段历练的LoRA进行参数动手化。第三阶段,辅导微调阶段。该阶段将MoE的门控聚集冻结,仅历练每个“巨匠”,将进一步加强模子的辅导随从能力。同期,该阶段的历练策略也适用于基座模子在其他卑劣任务微调的场景。
Awaker2.5-VL的三阶段历练经由
Awaker2.5-VL一共使用了1200万的辅导数据进行模子历练,其中包括700万的英文数据和500万的中语数据。英文数据主要着手于开源数据,包括Cambrian (2M)、LLaVAOneVision (4M)、Infinity-MM (800K)、MathV360k (360K)等。中语数据则是智子引擎团队的自建数据集,包括图文形色、图文问答、宗旨检测、翰墨识别等多种任务数据。
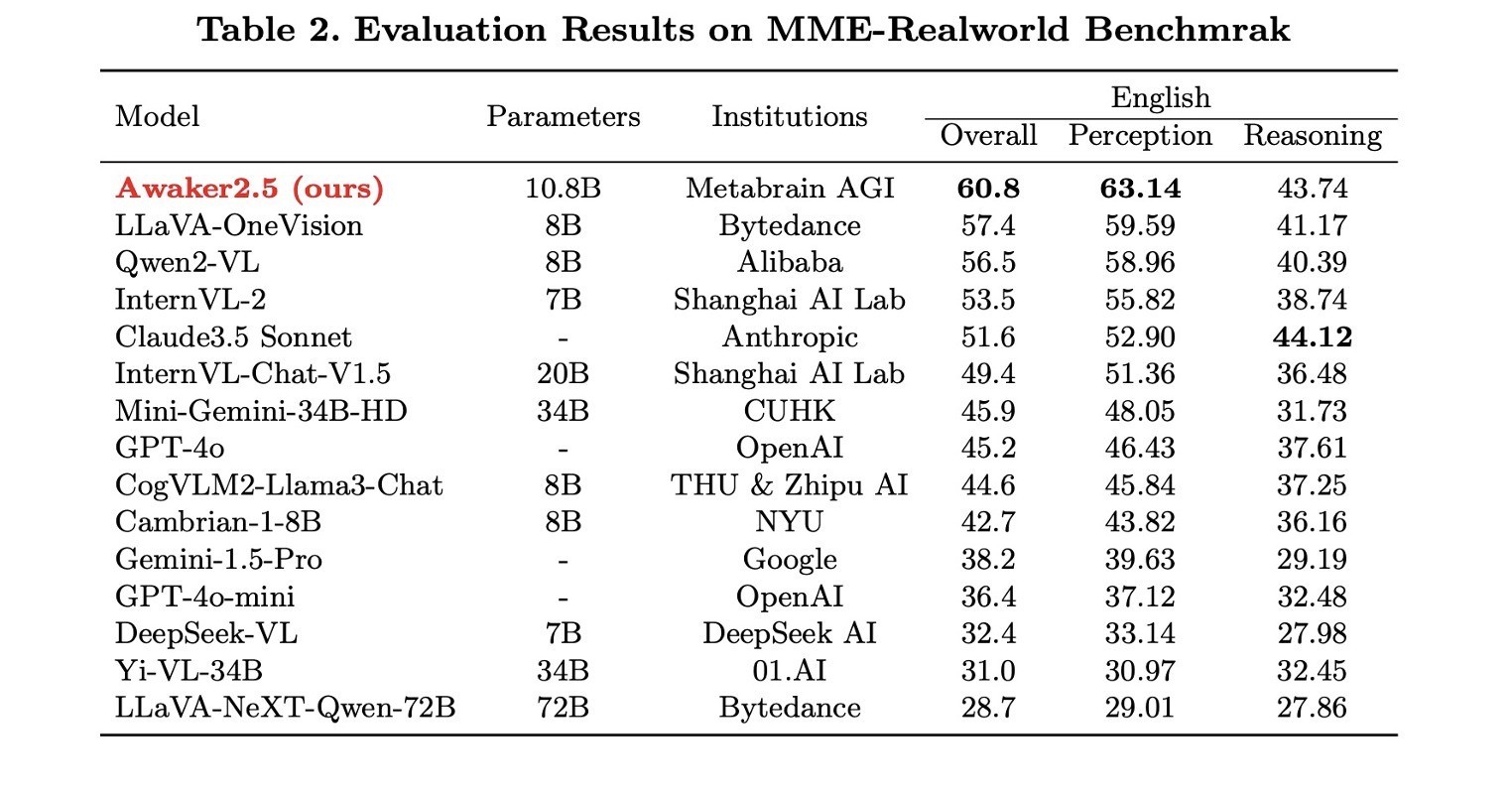
模子性能Awaker2.5-VL主要在MME-Realworld系列和MMBench系列Benchmark上离别进行了中语测评和英文测评。MME-Realworld是面前最难、领域最大多模态评测基准,而MMBench是主流多模态大模子参评最多的评测基准之一。
Awaker2.5-VL在MME-Realworld和MME-Realworld-CN都位列榜首,且是现在独一在该Benchmark上“合格”(迥殊60分)的模子。筹商到MME-Realworld主要面向自动驾驶、遥感、视频监控等复杂场景,Awaker2.5-VL在MME-Realworld上的出色发扬很好地展示它在落地哄骗中的弘远后劲。

Awaker2.5-VL离别在MMBench、MMBench_v1.1、MMBench_CN、MMBench_CN_v1.1四个榜单进行了测评,而且离别以英文能力平均分数(MMBench和MMBench_v1.1)和中语能力平均分数(MMBench_CN和MMBench_CN_v1.1)进行排序。Awaker2.5-VL在中语场景和英文场景均离别位列第9和第7。在同量级参数目的模子中,Awaker2.5-VL发扬远超其他模子。这即是说Awaker2.5-VL简略兼顾模子着力和资源耗尽,也进一步解释它具有极大的落地哄骗价值。


模子哄骗
2024年,智子引擎也曾奏效地将Awaker2.5-VL哄骗于多个复杂的本色场景,包括国度电网、社会处分、做事型机器东谈主等。在行将到来的2025年,智子引擎将不息探索Awaker2.5-VL更多的落地哄骗场景。为了饱读舞这种探索,智子引擎选择开源Awaker2.5-VL,基于战术巴合伙伴清昴智能的华为昇腾原生器具链MLGuider-Ascend,Awaker2.5-VL已适配昇腾全居品线,但愿更多生态伙伴简略参与进来。同期,为了加快国产化AI进度,Awaker系列开源模子与清昴智能已造成规范的昇腾国产决议,将上线至昇腾平台,迎接公共存眷和使用。
— 完 —
量子位 QbitAI · 头条号签约
存眷咱们,第一工夫获知前沿科技动态