中国电信TeleAI-t1-preview发布,逻辑推理才能超OpenAI标杆模子

中国电信东谈主工智能连系院近日文告,其倾力打造的“复杂推理大模子”TeleAI-t1-preview已认真面世,并将很快在天翼AI洞开平台上与公众碰头。该模子罗致先进的强化学习履行本事,通过引入探索与反想机制,权贵晋升了在逻辑推理与数学推导等复杂问题上的解答精度。
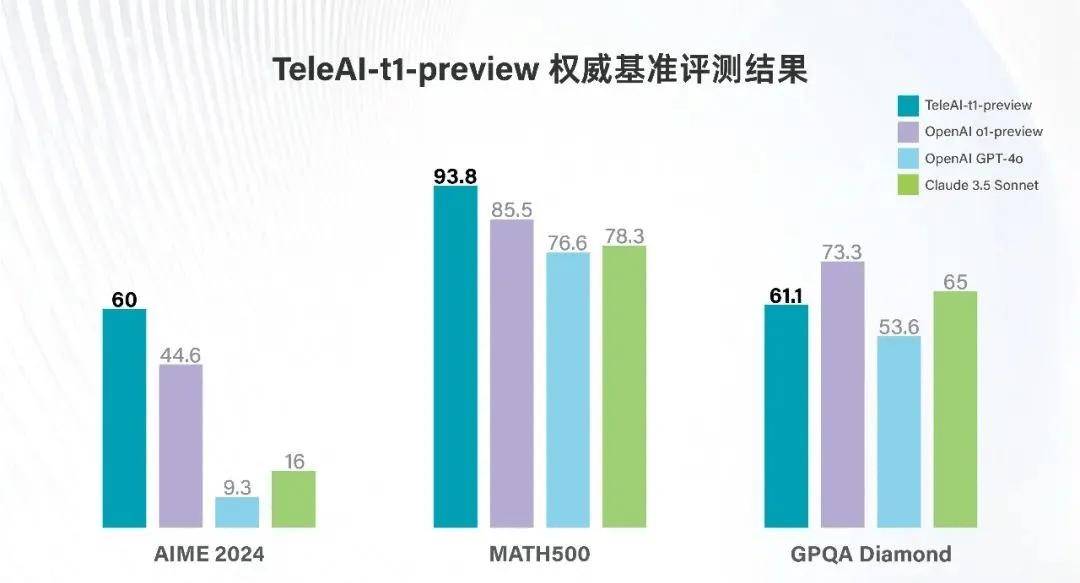
据官方先容,TeleAI-t1-preview在好意思国数学竞赛AIME 2024与MATH500两项泰斗基准测试中,辞别以60分和93.8分的优异成绩,远超OpenAI的o1-preview和GPT-4o等业界标杆模子。在连系生级别问答测试GPQA Diamond中,其泄露同样出色,得分越过GPT-4o,与Claude 3.5 Sonnet的性能不相高下。
评测线路,TeleAI-t1-preview在处理《九章算术》中的题目时,约略先对文言文进行精确长入和简化,再调节成当代汉语,并给出详备的数学推导流程和谜底。这一流程中,模子展现了将形象想维与综合想维通常一的才能,对所触及场景进行具象化想考,从而更好地长入题目。


尤为TeleAI-t1-preview还能严谨地进行古今单元换算,确保了谜底的准确性。这一竖立收获于中国电信东谈主工智能连系院在模子履行计策上的改进。
在数据准备阶段,连系院采集并构建了一个以数学为中枢、涵盖多学科的高质地推理数据集,为模子合适不同类型推理任务打下了坚实基础。还履行了一个格外的Judge Model,用于分析和评估模子长想考链路的正确性,为模子的反想和造作修正提供精确携带。
在监督微调(SFT)阶段,连系院罗致蒙特卡洛树搜索(MCTS)构造高质地长推理数据,同一每个门径的准确率和措置决策长度,聘请最优好意思满旅途。这不仅保证了推理谜底的准确性,还有用拉长了想考链路,使推理流程愈加细粒度。同期,期骗Judge Model对推理流程中正确率较低的旅途进行分析,指令模子对造作推理门径进行反想和修正,从而构造出高质地的想维链数据进行SFT履行。
在强化学习阶段,连系院稀奇构造了基于轨则的奖励模子(Rule-based Reward Model),提供准确奖励信号,通过在线强化学习算法进一步晋升模子的逻辑推理才能。这一系列改进举措,共同竖立了TeleAI-t1-preview在复杂推理限度的超卓泄露。