OpenAI Deep Research“被开源”:24小时顺利复现,揭秘背后期间细节

编译 | 陈骏达裁剪 | Panken
智东西2月8日音讯,24小时极速复现OpenAI Deep Research,还免费提供,这是开源AI社区Hugging Face作念出的新孝顺——一款开源的AI参议agent,不仅能胜任整理信息写论说的复杂任务,而且仅绽放一天就在严苛的通用AI助手基准测试中达到55%的准确率(OpenAI原功能是67%)。
DeepSeek-R1在国外的风物级爆火,加快OpenAI推出免费的o3-mini、Deep Research等新模子与功能。然则,DeepSeek开源计谋掀翻的前沿模子复现潮,让重大网友也曾不温顺于OpenAI的闭源系统,而是但愿用更低资本的开源系统收场雷同的恶果。
OpenAI的Deep Research能进行多法子自主参议、信息深度整合以及复杂任务的处理,OpenAI在博客中泄漏,Deep Research由一个大模子和一个里面Agent框架构成。
复当前,Hugging Face团队基于微软的开源Agent系统,并用代码Agent框架进行优化,让Agent用代码来计较、抒发其行动,这对进步系统弘扬的作用显贵。
该团队还建议,异日可通过加多复古的文献样式数目、建议对文献进行更细粒度处理的建议以及使用基于视觉的汇集浏览器,来进一步进步系统弘扬。
名目相连:https://huggingface.co/blog/open-deep-research
试用相连:https://m-ric-open-deep-research.hf.space/
一、代码Agent架构可显贵进步性能,运行资本镌汰30%Hugging Face团队本次复现OpenAI Deep Research的中枢任务即是Agent框架的搭建。Agent框架是大模子上一层的架构,用于指导大模子进行浏览网页、阅读PDF等操作,而且按照一系列法子组织上述操作。
将大模子整合进Agent框架可显贵进步性能弘扬。在多项基准测试中,仅需使用基础的开源通用Agent架构smolagents库,就能将几款最近发布的前沿模子的弘扬进步至高60分。
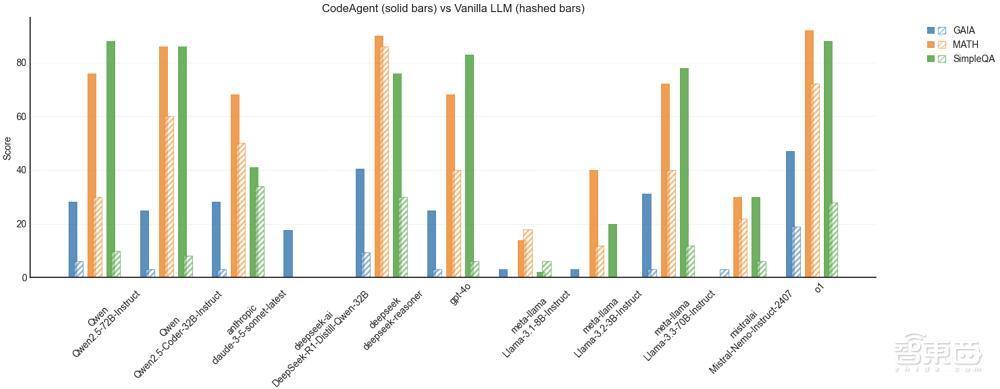
▲Agent框架能显贵进步大模子弘扬(图源:Hugging Face)
实质上,OpenAI也在发布Deep Research功能的博客著作中强调,在常识密集型的高难度基准测试“Humanity’s Last Exam”中,Deep Research的弘扬要彰着好于沉静运行的大模子。
在复现Deep Research功能时,Hugging Face团队主要接受代码Agent来进步传统Agent架构的弘扬。先前参议骄矜,让Agent用代码来计较、抒发其行动具有4个上风,尤其是在抒发复杂的行动序列时。
1、鄙人决议例中,用代码来暗意行动比JSON要精辟许多。这一序列需要运行4个并行流,每个流包含5个连气儿行动。在JSON中,你需要生成20个JSON块,每个块在单独的法子中;而若用代码暗意,只需1个法子。
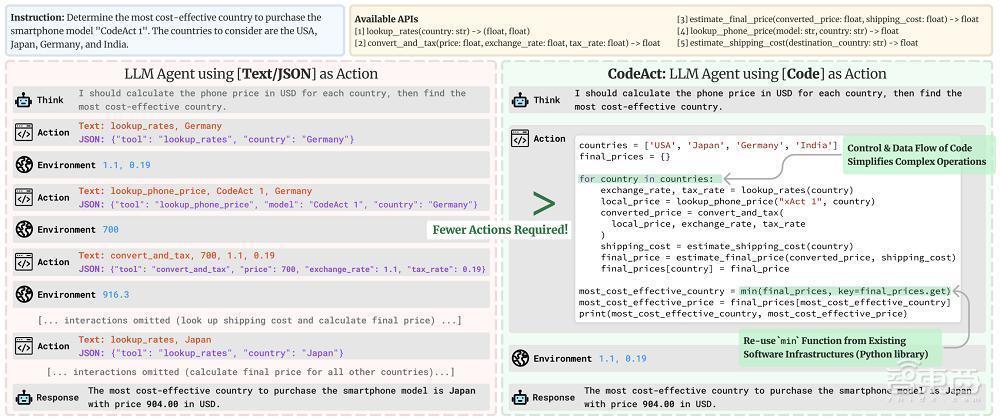
▲参议开首:Paper page – Executable Code Actions Elicit Better LLM Agents
平均而言,论文骄矜代码行动比JSON少30%的法子,这意味着生成的token也相应减少。由于大模子调用通常是Agent系统的主要资本,这意味着Agent系统的运行资本镌汰了约30%。
2、用代码来暗意行动还能更便捷地再诓骗常见库中的器具。
3、这种系统在基准测试中的弘扬更好,因为大模子在磨真金不怕火时平凡来去了代码数据,这种行动抒发形式对它们来说更为直不雅。
4、更好的气象处理才调:在多模态任务中,若是需要存储图像、音频等内容后续使用,只需将其四肢变量分派给气象。但在JSON中,必须让大模子在字典键中定名它,大模子后续能否贯串和使用也如故未知数。
同期,Agent系统需要配备正确的器具集,Hugging Face的复现团队使用了微软参议院现成的的Magentic-One Agent,试图用最低的复杂性获取最高的性能。器具围聚包含2个器具:
1、一个汇集浏览器。天然像Operator这么的齐备汇集浏览器交互需要达到全性能,但Hugging Face团队现在先使用了一个苟简的基于文本的汇集浏览器,四肢认识考据。
2、一个苟简的文本查验器,大略读取多数文本文献样式。
二、远超开源SOTA系统,还有三大进步空间为测试上述系统的性能,Hugging Face团队使用了GAIA这一全面且难度较高的Agent测试基准,触及许多基于谎言语模子的挑战。
下方是一个测试围聚的难题:
“在2008年的画作《乌兹别克斯坦刺绣》中展示的生果,哪些被用作1949年10月邮轮早餐菜单的一部分,该邮轮自后被用作电影《临了的飞翔》的浮动谈具?请以逗号分隔列出这些生果,按照画作中从12点位置启动按顺时针标的摆设的生果规则,使用每个生果的复数样式。”
此类问题对Agent系统建议了多个挑战:识别生果需要用到多模态才调;征集信息时需要贯串信息间的相互依赖关联;输出回当令需要按照指定的样式。此外,系统还需将问题处分的轨迹按正确规则串联起来。
处分此问题需要高档计较才调解严格的践诺,这两个鸿沟在使用时单独使用大模子时会遭受好多贫乏。
在GAIA的世界名次榜上,GPT-4在莫得任何Agent蛊惑的情况下,连7%的考据集分数皆够不上。但通过Deep Research,OpenAI在考据集上达到了67.36%的分数,进步了一个数目级。
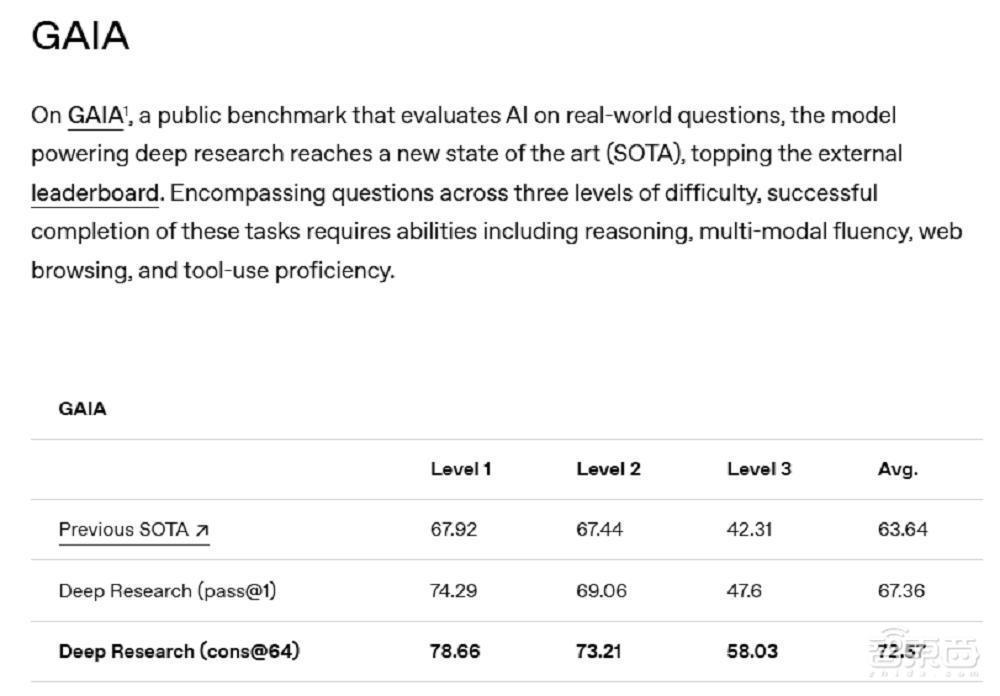
▲Deep Research在GAIA上的得益(图源:OpenAI)
在Hugging Face 24小时的复现尝试中,代码Agent的使用对系统的举座弘扬进步彰着。之前,Magentic-One是GIGA测试中弘扬最好的开源系统,Hugging Face团队将其弘扬从46%进步至55.15%,这种性能进步主要归功于让Agent以代码的样式编写其动作。
当切换到以JSON而不是代码编写动作的尺度Agent时,琢磨蛊惑的考据集性能会立即下落到33%傍边。
Hugging Face团队合计,异日此类系统还不错从三方面进行校正:
1、彭胀可读取的文献样式数目。
2、建议对文献进行更细粒度处理的建议。
3、替换为基于视觉的网页浏览器(开源地址)。
结语:DeepSeek掀翻的开源激越执续DeepSeek凭借其透明、可操作性强的发布与开源模式,成为了全球AI模子开源的最好履行案例之一。
Hugging Face本次对OpenAI Deep Reasearch的复现,也恰是适合了DeepSeek掀翻的开源激越。这一趋势有望让前沿AI模子的期间逾越惠及更重大的参议群体。
开首:Hugging Face