前端枢纽员请提神!首个截图就能生成当代前端代码的AI来了 | 开源

金磊 整理自 投稿
量子位 | 公众号 QbitAI
咫尺截图生成代码,照旧来到了一个新高度——
⾸个⾯向当代前端代码⽣成的多模态⼤模子处置⽅案,来了!
而且是开源的那种。

(注:当代前端代码建树具有组件化、景象照管和数据驱动渲染、建树模范严格以及动态交互性强等特色。这些特色相互关系,共同组成了当代前端建树的复杂体系,对代码生成提倡了更高要求。如基于React、Vue等框架的建树。)
这个模子叫作念Flame,话未几说,平直来看效果。
举例截图让AI生成底下这个界面:
Flame模子在“看”完图片之后,给出来的代码是这么:
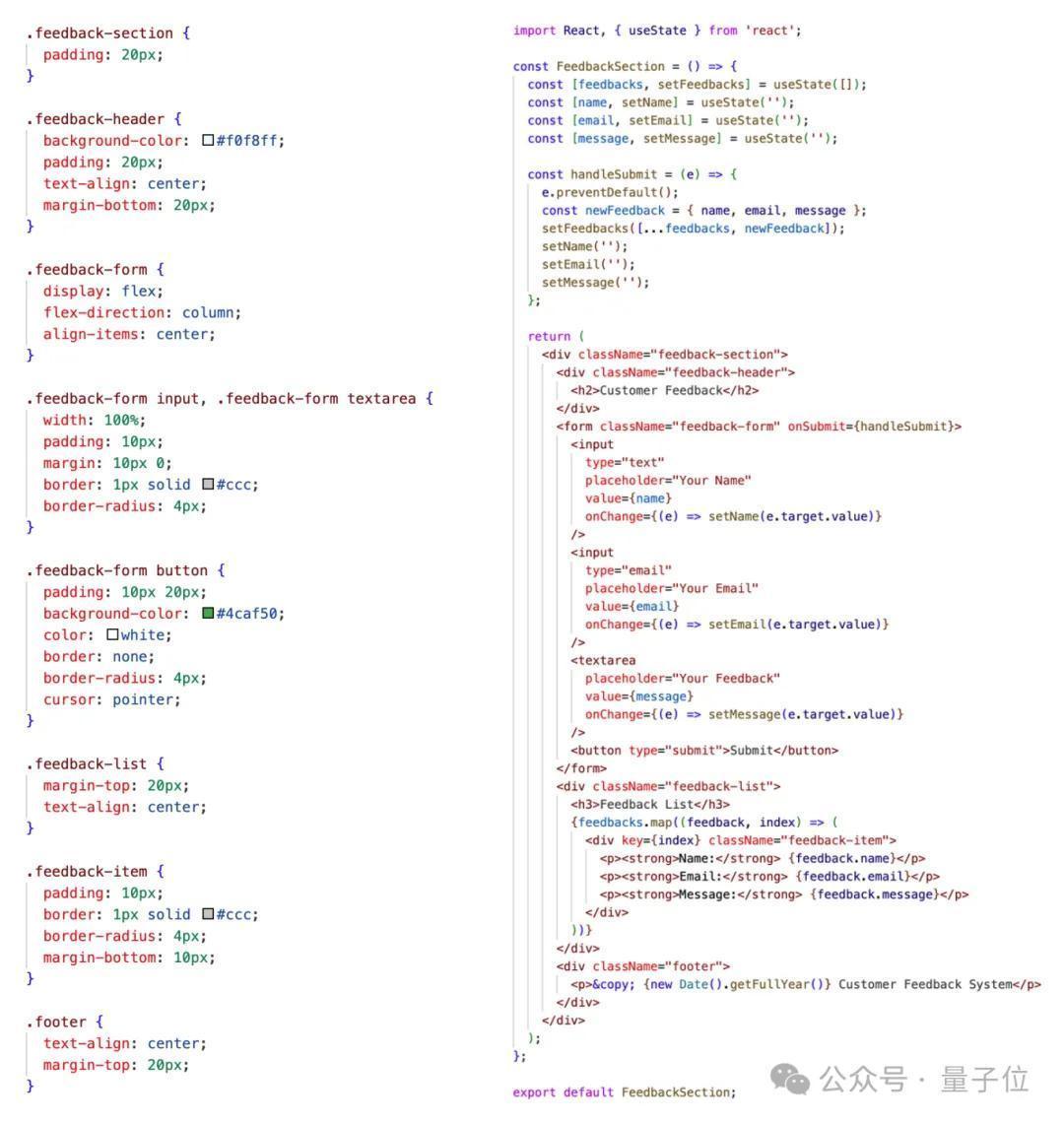
不丢丑出,Flame⽣成代码彰着是适应当代前端建树模范的,包括⽐较显着的外联神态以及模块化组件结构。
同期在组件的齐备中正确界说了组件的各个景象、事件反映、以及基于数据的组件动态渲染。
关系词,诚如GPT-4o这么顶尖的SOTA模子,可能也与当代前端建树的核⼼需求背说念⽽驰,因为局限在于端到端复刻绸缪图的过程中只可产出静态组件。
举例相通的界面,GPT-4o的解法是这么的:
问题根源在于这类静态代码既⽆法⽀撑模块化架构,也难以⽀撑动态交互。
每个组件齐是“⼀次性产品”,任何幽微的需求建树和迭代,可能齐要建树者建树⼤量定制化代码,甚⾄是推倒重来。
那么Flame模子又是何如处置这个问题的呢?
中枢问题:数据稀缺⼤型视觉语⾔模子(LVLM)在⽣成专科前端代码上推崇不尽⼈意的根底原因在于数据稀缺。
当代前端建树经过⾮常复杂,⽐如像React这么的前端框架,强调组件化、景象照管和数据驱动的渲染⽅式。
这就要求⽣成的代码不仅要能⽤,还要适应建树模范,具备动态性和反映性。
然⽽,开源社区中⽀捏前端建树的⾼质料图像-⽂本(代码)数据集至极稀缺。
像websight这么的数据集只触及静态HTML,不适⽤于当代前端建树。
集会并构建⾼质料的检察数据⾯临好多挑战:
何如从巨匠代码库中索要有用代码片断?如安在保捏原有代码效果的情况下进行渲染?何如⽣成适应⼯程师俗例的⼤量、各样化数据?针对这些问题,Flame模子的团队给出了解法即是数据合成。
为进步LVLM在前端代码⽣成能⼒,咱们绸缪了⼀整套⾃反想的智能体⼯作流,⽤于⽣成前端建树场景下的⾼质料数据。
该⼯作流不仅能⾃动从巨匠代码库中索要真实数据,还大概⾃主合成数据,⽣成专科、各样化的前端代码。
团队绸缪并齐备了3种合成⽅法:
基于进化的数据合成(Evolution-Based Synthesis)
模仿WizardLM的Evol-Instruct⽅法,通过速即进化⽣成各样化的代码。它采⽤两种政策:⼴度进化和深度进化。
⼴度进化通过更正代码的功能和视觉⻛格,⽣成新变体;深度进化则通过加多代码的技艺复杂度,优化组件处理、景象照管和性能,进步代码的可靠性和可保重性。
通过握住进化,不错得到⼤量笼罩不同需求的前端代码。
基于瀑布模子的数据合成(Waterfall-Model-Based Synthesis)
模拟传统软件建树的瀑布流模子,确保⽣成的代码结构显着、逻辑⼀致。从需求分析运转,推导出系统功能需求,绸缪UI布局和架构,保证代码适应当代前端建树的模块化和可扩展性要求。
接着,通过多轮迭代,将需求振荡为具体的、可复⽤的前端组件和⻚⾯。这种⽅法⽣成的代码逻辑显着,适应复杂功能的建树任务。
基于增量建树的数据合成(Additive Development Synthesis)
在现存代码基础上,迟缓加多功能和复杂性。通过迟缓集成景象照管、交互逻辑或API等功能模块,⽣成的代码能更好地满⾜本色建树需求。
这种⽅法强调迟缓进步代码的功能和复杂度,确保每次扩展齐最⼤可能适应最好延迟。
上述的三种⽅法不仅丰富了数据集的范围和各样性,还确保了数据质料与本色应⽤价值。
这些⽅法大概低老本⼤范围合成特定前端框架的图⽂数据,借助上述⽅法,Flame团队针对React框架构建了逾越400k的多模态数据集。
同期,基于瀑布模子和增量建树的⽅法还⽀捏多图场景下的数据合成、视觉想维链的合成,为更复杂场景下的前端代码⽣成提供了更多可能。
Flame:针对前端建树场景的VLMFlame团队⼈⼯构建了⼀套包含80说念测试题⽬的⾼质料测试集并通过检阅后的Pass@k来评测多模态模子的前端代码⽣成能⼒。
要是⽣成的代码大概通过编译考据、适应编码模范,而况所渲染出的⻚⾯与输⼊的绸缪图⾜够相似,则以为该代码适应要求。
评测末端显⽰,面前顶级模子如GPT-4o,Gemini 1.5 Flash因其⽣成代码主要为静态代码,严重偏离代码模范,使其最⾼Pass@1仅为11%,⽽Flame在交流条款下达到了52%+,展现出了极⼤的潜⼒。
同期,同期,Flame仅⽤20w傍边的数据量级即获取以上效果,进⼀步考据了上述数据合成⽅法的价值以及⾼质料数据集在多模态模子能⼒进步中的要害作⽤。
△左:测试图;右:Flame效果图
值得一提的是,将检察数据、数据合成经过、模子及测试集照旧全⾯开源,感意思的小伙伴飞速去望望吧~
GitHub地址:https://github.com/Flame-Code-VLM/Flame-Code-VLM/blob/main/README.md
— 完 —
量子位 QbitAI · 头条号签约
温雅咱们,第一时分获知前沿科技动态