OpenAI更强系统来了,通用东说念主工智能真是垂手而得吗?

"机器究竟还需要多永劫期,才能着实具备东说念主类大脑的融会技艺?"这个困扰东说念主工智能领域数十年的根人性问题,在2024年末再次成为群众科技界的焦点。
当东说念主工智能在图像识别、当然言语处理等特定领域不竭冲突时,一个更具挑战性的测度打算遥远敷衍唐塞:让机器赢得举一反三的知勤奋、概述见解的推理技艺,以及如同东说念主类一般筹谋和调配融会资源的技艺。
就在这场对于机器智能极限的络续争辩中,OpenAI最近发布的新式东说念主工智能系统,为这个传统命题注入了新的变数。这家总部位于旧金山、因开拓ChatGPT而风生水起的AI巨头,于9月发布了被称为O1的新一代大型言语模子(LLM)系统。而就在本月,业内又传出OpenAI正在开拓代号为O3的更强盛系统,这个被称为“通用东说念主工智能(AGI)前奏”的名目引发了新一轮关爱。与以往的AI模子比较,从O1到O3的时刻路子皆展现出了一种更接近东说念主类融会款式的初始机制,这些冲突性进展正在重新界说咱们对东说念主工智能后劲的融会。
AGI一朝齐备,可能为东说念主类带来前所未有的冲突:从阵势变化的管制,到流行病的防控,再到癌症、阿尔茨海默病等恶疾的攻克。关联词,这么广漠的力量也可能带来不细目性,并对东说念主类组成潜在风险。加拿大蒙特利尔大学深度学习计划员Yoshua Bengio暗意:“东说念主类对AI的误用或失控,皆可能导致严重后果。”
连年来LLM的创新性进展激励了对于AGI大略行将到来的千般意想。但一些计划东说念主员暗意,洽商到LLM的构建和磨真金不怕火款式,它们单靠自己不足以齐备AGI,“仍然短少一些关键部分。”
毫无疑问,对于AGI的问题如今比以往任何时候皆愈加蹙迫和重要。“我泰半生皆以为,驳斥AGI的东说念主是不对惯例的,”亚利桑那州立大学的筹划机科学家Subbarao Kambhampati说,“但如今,每个东说念主皆在驳斥它。你不成称通盘东说念主皆‘不对惯例’了。”
01 AGI辩白为何转向“通用东说念主工智能”(AGI)这一术语大致在2007年头度参预主流视线,其时它看成同名竹素的标题由AI计划东说念主员Ben Goertzel和Cassio Pennachin推出。固然这一术语的确切含义尚不解确,但每每指代具有类似东说念主类推理和泛化技艺的AI系统。在东说念主工智能发展的大部分历史中,东说念主们普遍以为AGI仍然是一个尚未齐备的测度打算。举例,谷歌DeepMind开拓的AlphaGo范例专为围棋对弈而遐想。它在围棋领域打败了顶尖的东说念主类棋手,但其超东说念主技艺仅限于围棋,也即是说,这是它独一的擅长领域。
LLM[1]的新技艺正在绝对调动这一场面。与东说念主类大脑相似,LLM领有等闲的技艺,这使得一些计划东说念主员清静洽商某种样子的通用东说念主工智能可能行将到来[1],以致依然存在。
当你洽商到计划东说念主员仅部分了解LLM怎样齐备这一测度打算时,这种技艺的广度愈加令东说念主惧怕。LLM是一种神经网罗,其灵感大致起首于东说念主脑。它由分层摆设的东说念主工神经元(或筹划单位)组成,这些层与层之间的联接强度通过可调参数暗意。在磨真金不怕火流程中,强盛的LLM——举例o1、Claude(Anthropic公司开拓)以及谷歌的Gemini——依赖一种称为“下一个词元掂量(next token prediction)”的设施。在该设施中,模子会肖似输入已被分割的文本样本(即词元块)。这些词元不错是通盘这个词单词或仅仅一组字符。序列中的终末一个词元被荫藏或“屏蔽”,并条目模子对其进行掂量。然后,磨真金不怕火算法将掂量与屏蔽词元进行比较,并诊疗模子的参数,使其下次能够作念出更好的掂量。
这一流程不竭肖似——每每使用数十亿对话片断、科学文本和编程代码——直到模子能够可靠地掂量荫藏的词元。在此阶段,模子参数已捕捉到磨真金不怕火数据的统计结构偏激中包含的学问。随后参数被固定,模子使用它们对新的查询或“教导”生成掂量,这些教导不一定在其磨真金不怕火数据中出现过,这一流程被称为“推理”。
一种称为“Transformer”的神经网罗架构的使用,使LLM的技艺权贵超过了之前的建立。Transformer使得模子能够学习到某些词元对其他词元有荒谬强的影响力,即使它们在文本样本中相距甚远。这使得LLM能够以看似师法东说念主类的款式解析言语——举例,区别以下句子中“bank”一词的两种含义:“当河岸(bank)泛滥时,激流损坏了银行(bank)的ATM,导致无法取款。”
这种设施在多种应用场景中取得了权贵死心,举例生成筹划机范例来惩办用当然言语样子的问题、记忆学术著作和恢复数学问题。
跟着LLM限制的增大,一些新的技艺也随之出现——若是LLM弥漫大,AGI也可能出现。其中一个例子是“想维链(CoT)教导”。这种设施包括向LLM示范怎样将复杂问题领会为更小的智商加以惩办,或径直教导其按智商解答问题。关联词,对于较小限制的LLM,这一流程并不具备权贵的效果。
02 LLM的技艺规模根据OpenAI的先容,“CoT教导”已被整合到o1的初始机制中,成为其强盛功能的中枢组成部分。谷歌前AI计划员Francois Chollet指出,o1配备了一个CoT生成器,该生成器能够针对用户查询生成巨额CoT教导,并通过特定机制筛选出最好教导。
在磨真金不怕火中,o1不仅学习怎样掂量下一个词元,还掌持了针对特定查询选拔最好CoT教导的技艺。OpenAI暗意,恰是收获于CoT推理的引入,o1-preview(o1的高档版块)在海外数学奥林匹克竞赛(一项面向高中生的群众著明数学赛事)的预选测验中正确惩办了83%的问题。比较之下,OpenAI此前最强盛的模子GPT-4o在淹没测验中的正确率仅为13%。
关联词,尽管o1的复杂性令东说念主真贵,Kambhampati和Chollet均以为,它仍存在彰着的局限性,并未达到AGI的圭臬。
举例,在需要多步筹谋的任务中,Kambhampati的团队发现,固然o1在最多16步的筹谋任务中进展优异,但当任务复杂度加多至20至40步时,其性能马上着落[2]。
Chollet在挑战o1-preview时也发现了类似的局限性。他遐想了一项概述推理与泛化测试,以评估通往AGI的发展程度。测试继承视觉谜题的样子,惩办这些问题需要寻查示例来推断出概述轨则,并以此来惩办类似新问题。死心骄贵,东说念主类明白更容易作念到。Chollet进一步指出:“LLM无法着实顺应新事物,因为他们基本上莫得技艺将我方掌持的学问,动态地进行复杂的重组,以顺应新的环境。”
03 LLM能否迈向AGI?那么,LLM是否有技艺最终迈向AGI呢?
值得戒备的是,底层的Transformer架构不仅能够处理文本,还适用于其他类型的信息(如图像和音频),前提是不错为这些数据遐想合适的词元化设施。纽约大学计划机器学习的Andrew Wilson偏激团队指出,这可能与不同类型数据分享的一个特质说合:这些数据集的“Kolmogorov复杂度”较低,即生成这些数据所需的最短筹划机范例的长度较短[3]。
计划还发现,Transformer在学习低Kolmogorov复杂度的数据模式方面进展尤为出色,而这种技艺会跟着模子限制的增大而不竭增强。Transformer具备对多种可能性进行建模的技艺,这提高了磨真金不怕火算法发现问题的相宜惩办决策的概率,而这种“进展力”会跟着模子限制的增前途一步增强。Wilson暗意,这些是“通用学习所需的一些关键身分”。
尽管Wilson以为AGI面前仍驴年马月,但他暗意,使用Transformer架构的LLM和其他AI系统已具备一些类似AGI步履的关键特质。
关联词,基于Transformer的LLM也清晰出一些固有的局限性。
最初,磨真金不怕火模子所需的数据资源正在渐渐枯竭。专注于AI趋势计划的旧金山EpochAI计划所测度[4],公开可用的磨真金不怕火文本数据集可能会在2026年至2032年之间消费。
此外,尽管LLM的限制不竭增大,其性能提高的幅度却不足以往。尚不解确这是否与数据中新颖性减少说合(因为大部分数据已被使用过),或是源于其他未知原因。后者对LLM来说是个坏兆头。
Google DeepMind的伦敦计划副总裁RaiaHadsell提议了另一项质疑。她指出,尽管基于Transformer的LLM具备强盛功能,其单一的测度打算——掂量下一个词元——过于局限,难以齐备着实的AGI。她建议,构建能够一次性或以合座款式生成惩办决策的模子,可能更接近齐备AGI的可能。用于构建此类模子的算法已在一些现存的非LLM系统中得以应用,举例OpenAI的DALL-E,该系统能够根据当然言语样子生成传神以致超执行的图像。关联词,这些系统无法与LLM的等闲功能相比好意思。
04 构建AI的宇宙模子对于怎样鼓动AGI发展的冲突性时刻,神经科学家的提供了直观性的重要启示。他们以为,东说念主类智能的根源在于大脑能够构建一个“宇宙模子”,即对周围环境的里面表征。这种模子能够模拟不同的行为决策并掂量后来果,从而复旧筹谋与推理。此外,通过模拟多种场景,这种模子不错将特定领域中学到的手段泛化到全新任务中。
一些计划陈说宣称,已有笔据标明LLM里面可能变成了初步的宇宙模子。在一项计划中[5],麻省理工学院的Wes Gurnee和Max Tegmark发现,当LLM使用包含宇宙多地信息的数据集进行磨真金不怕火时,跟着等闲应用,LLM能够在里面对周围宇宙变成相应的表征。关联词,其他计划东说念主员指出,面前尚无笔据标明这些LLM垄断宇宙看成模子进行模拟或因果相干学习。
在另一项计划中[6],哈佛大学筹划机科学家KennethLi偏激共事发现,一个袖珍LLM在使用玩家不才Othello棋时的步法看成磨真金不怕火数据后,学会了里面表征棋盘情状的技艺,并垄断这种表征正确掂量了下一步的正当棋步。
关联词,其他计划标明,面前AI系统构建的宇宙模子可能并不可靠。在一项计划中[7],哈佛大学的筹划机科学家Keyon Vafa偏激团队使用纽约市出租车行程的转弯数据集磨真金不怕火了一个基于Transformer的模子,该模子以接近100%的准确率完成了任务。通过分析模子生成的转弯序列,计划东说念主员发现模子依赖一个里面舆图来完成掂量。关联词,这个里面舆图与曼哈顿的骨子舆图险些毫无相似之处。
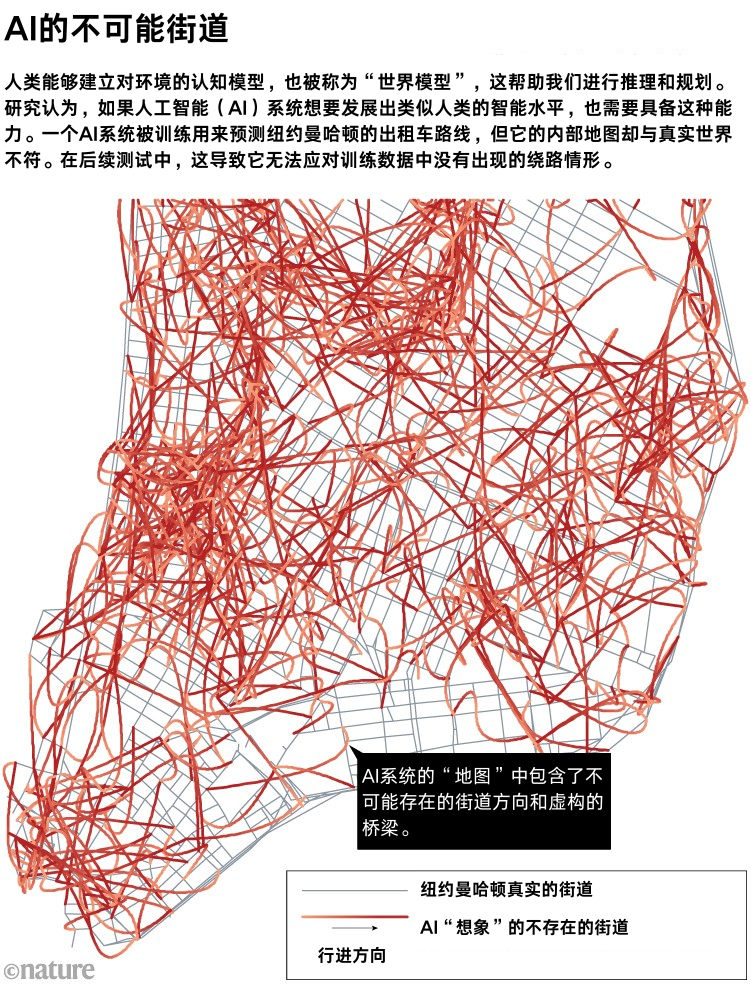
▷AI的不可能的街说念. 图源:[7]
Vafa指出,“该舆图包含物理上不可能的街说念标的,以及向上其他街说念的高架说念路。”当计划东说念主员诊疗测试数据,加入磨真金不怕火数据中未出现的偶而绕说念时,模子无法掂量下一次转弯,标明其对新情境的顺应技艺较弱。
05 反馈的重要性GoogleDeepMind位于加利福尼亚山景城的AGI计划团队成员DileepGeorge指出,面前的LLM勤奋一个关键特质:里面反馈。东说念主类大脑具有等闲的反馈联接,使信息能够在神经元层之间齐备双向流动。这种机制使感官系统的信息不错流向大脑的高档层,以创建反馈环境的宇宙模子。同期,宇宙模子的信息也不错向下传播,指点进一步感官信息的获取。这种双向流程对感知至关重要,举例,大脑垄断宇宙模子推断感官输入的潜在原因。此外,这些流程还复旧筹谋,垄断宇宙模子模拟不同的行为决策。
关联词,面前的LLM仅能以附加款式使用反馈。举例,在o1中,里面的CoT教导机制,通过生成教导协助恢复查询,并在最毕生成谜底前反馈给LLM。但正如Chollet的测试所骄贵,这种机制并不成确保概述推理技艺的可靠性。
Kambhampati等计划东说念主员尝试为LLM添加一种称为考证器的外部模块。这些模块在特定崎岖文中查验LLM生成的谜底,举例考证旅行测度打算的可行性。若是谜底不够完善,考证器会条目LLM重新初始查询[8]。Kambhampati的团队发现,借助外部考证器的LLM,在生成旅行测度打算时进展权贵优于平方LLM,然而计划东说念主员需要为每个任务遐想挑升的考证器。“莫得通用考证器,”Kambhampati指出。比较之下,AGI系统可能需要自主构建考证器,以顺应不怜悯境,就像东说念主类垄断概述轨则确保在新任务中进行正确推理相似。
基于这些主见开拓新式AI系统的计划仍在初步阶段。举例,Bengio正在探索怎样构建不同于刻下基于Transformer架构的AI系统。他提议了一种被称为“生成流网罗(generative flow networks)”的设施,旨在使单一AI系统既能构建宇宙模子,又能垄断这些模子完成推理与筹谋。
LLM濒临的另一个要紧荫庇是其对数据的广漠需求。伦敦大学学院表面神经科学家Karl Friston提议,改日的AI系统可通过自主决定从环境中采样数据的数目来提高服从,而非粗浅地吸收通盘可用数据。他以为,这种自主性可能是AGI所必需的。“在刻下的大型言语模子或生成式AI中,尚无法体现这种着实的自主性。若是某种AI能够齐备一定程度的自主选拔,我以为这将是迈向AGI的关键一步。”
能够构建灵验宇宙模子并集成反馈回路的AI系统,可能会权贵减少对外部数据的依赖。这些系统能够通过初始里面模拟,提议反事实假定,并借此齐备纠合、推理与筹谋。举例,2018年,计划东说念主员DavidHa和Jürgen Schmidhuber陈说[9],他们开拓了一种神经网罗,该网罗可高效构建东说念主工环境的宇宙模子,并垄断此模子磨真金不怕火AI驾驶臆造赛车。
若是你对这种自主性AI系统的见解感到不安,你并不是一个东说念主。除了计划怎样构建AGI,Bengio还积极倡导在AI系统的遐想和监管中引入安全性。他以为,计划应关爱磨真金不怕火能够保证自己步履安全的模子,举例诞盼望制来筹划模子违犯某些特定安全敛迹的概率,并在概率过高时拒却遴选行为。此外,政府需要确保AI的安全使用。“咱们需要一个民主流程来确保个东说念主、公司以致军方,以对公众安全的款式使用和开拓AI。”
那么,齐备AGI是否可能?筹划机科学家以为莫得意义不这么以为。“莫得表面上的荫庇,”George说。圣达菲计划所(Santa FeInstitute)的筹划机科学家Melanie Mitchell暗意高兴:“东说念主类和一些其他动物依然证明这小数是可行的。在旨趣上,我以为生物系统与由其他材料制成的系统之间不存在职何荒谬的各别,能够拦阻非生物系统变得智能。”
尽管如斯,对于AGI的齐备期间,学术界仍然勤奋共鸣:掂量范围从几年之内到至少十年以后。George指出,若是AGI系统被创造出来,咱们将通过其步履进展来阐发其存在。而Chollet则怀疑它的到来会相配低调:“当AGI到来时,它可能不会像你瞎想的那样可想而知或掀动风波。AGI的全面后劲需要期间冉冉清晰。它将最初被发明,然后经过推广和应用,最终才会着实调动宇宙。”